很多人都知道,網(wǎng)站的信息采集非常的重要,可以從別的網(wǎng)站里的數(shù)據(jù)采集過(guò)來(lái)給自己的網(wǎng)站使用,所以就需要用到QueryList插件了,下面就系統(tǒng)的講一下在thinkphp6下是如何使用QueryList的。
首先是下載QueryList的文件,存放到extend/Caiji里。
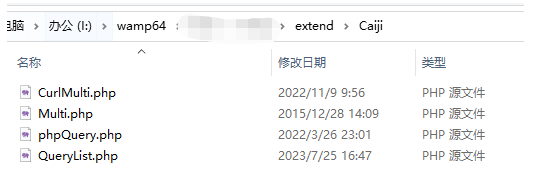
然后是引入文件,如下圖所示:
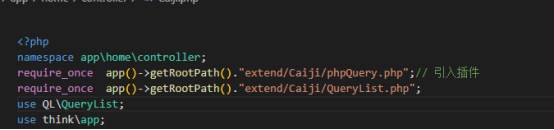
這里需要提一下,引入的文件必須在namespace app\home\controller的下面,否則會(huì)程序會(huì)報(bào)錯(cuò),引入的代碼:
require_once app()->getRootPath()."extend/Caiji/phpQuery.php";// 引入插件
require_once app()->getRootPath()."extend/Caiji/QueryList.php";
use QL\QueryList;
app()->getRootPath()是指引入文件根路徑,例如這里是I:/wamp64/www/。
現(xiàn)在來(lái)講使用,其實(shí)采集網(wǎng)站數(shù)據(jù)除非就是打開(kāi)要采集網(wǎng)站的指定的URL,打開(kāi)后頁(yè)面后,匹配相關(guān)的標(biāo)簽,得到我們要采集的數(shù)據(jù)的一個(gè)數(shù)組,然后對(duì)數(shù)組進(jìn)行一系列的處理后,得到我們想到的數(shù)據(jù),然后將這些數(shù)據(jù)寫(xiě)入到數(shù)據(jù)庫(kù)表里,就基本完成了。
例如我們打開(kāi)某個(gè)頁(yè)面,代碼如下:
$html = '某個(gè)網(wǎng)站的URL';
$rules = [
'title'=>['.article__title','text'],
'lay'=>['.meta-info-list li:eq(2) a','text'],
'lay2'=>['.meta-info-list li:eq(3) a','text'],
'content'=>['.article-content>.content','html'],
];
$data_list = QueryList::Query($html,$rules)->data;
其中title是新聞的標(biāo)題,如下圖所示,這里我們用text方式獲取.article__title里的純文本就行

還有l(wèi)ay和lay2是獲取文章的作者,lay是每指.meta-info-list 的第二個(gè)li的純文本text,lay2是.meta-info-list第三個(gè)li的text,如下圖所示:

content是指新聞的具體內(nèi)容了,處理數(shù)據(jù)也是整個(gè)最復(fù)雜的,這里包括去除一些不需要的內(nèi)容,獲取遠(yuǎn)程的圖片地址,并下載圖片到本地上等都需要在此操作的,content獲取的是.article-content>.content的html,即帶有html屬性標(biāo)簽的內(nèi)容。

獲取這些內(nèi)容后,我們先刪除<noscript></noscript>里的內(nèi)容,如下圖所示:

$content = preg_replace('#<noscript[^>]*?[^>]*>(.*?)</noscript>#is', '', $content);使用該正則表達(dá)式即可刪除<noscript></noscript>和里面的內(nèi)容。
由于內(nèi)容里存在圖片,如下圖所示:
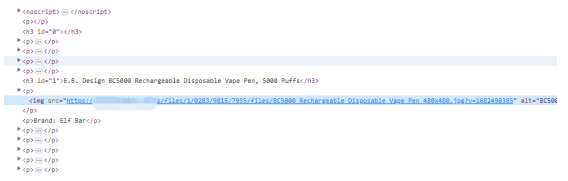
所以我們還要對(duì)content進(jìn)行篩選,得到圖片的數(shù)組,代碼如下:
$rules2 =[
'picture_list'=>['img','src']
];
$data2 = QueryList::Query($content,$rules2)->data;//獲得圖片的一個(gè)二維數(shù)組,然后再循環(huán)圖片,下載圖片保存到本地上。
處理以上事情后,就可以將處理后的數(shù)據(jù)寫(xiě)入到數(shù)據(jù)表中了,采集也就完成了。
如沒(méi)特殊注明,文章均為方維網(wǎng)絡(luò)原創(chuàng),轉(zhuǎn)載請(qǐng)注明來(lái)自http://www.sdlwjx666.com/news/6857.html





