最近有客戶問到,微信公眾號(hào)發(fā)布了一篇文章,可否直接同步到網(wǎng)站來發(fā)布,這樣可以節(jié)省時(shí)間,無需重復(fù)操作,節(jié)省文章發(fā)布的工作量!
根據(jù)方維網(wǎng)絡(luò)微信公眾號(hào)接口研究和發(fā)現(xiàn),微信公眾號(hào)接口也是變來變?nèi)ィ郧拔恼掳l(fā)布都會(huì)生成一個(gè)圖文素材,然后有接口可以獲取這個(gè)圖文素材,可以解決這個(gè)客戶提出的問題。
不過現(xiàn)在圖文素材改為草稿箱,然后有接口可以獲取草稿箱的文章,所以現(xiàn)在要獲取文章,需要通過接口獲取草稿箱的內(nèi)容,但是呢?這個(gè)草稿箱又沒有同步以前圖文素材的內(nèi)容。
所以如果需要獲取歷史素材,需要通過以前的圖文素材接口獲取后再加上獲取草稿箱的接口來實(shí)現(xiàn),但這些都是素材,也存在沒有發(fā)布的內(nèi)容,這點(diǎn)沒法區(qū)分。
有這個(gè)缺陷主要是公眾號(hào)沒有接口可獲取已群發(fā)的文章,不知道是居于何種原因考慮。官方說明如下截圖:
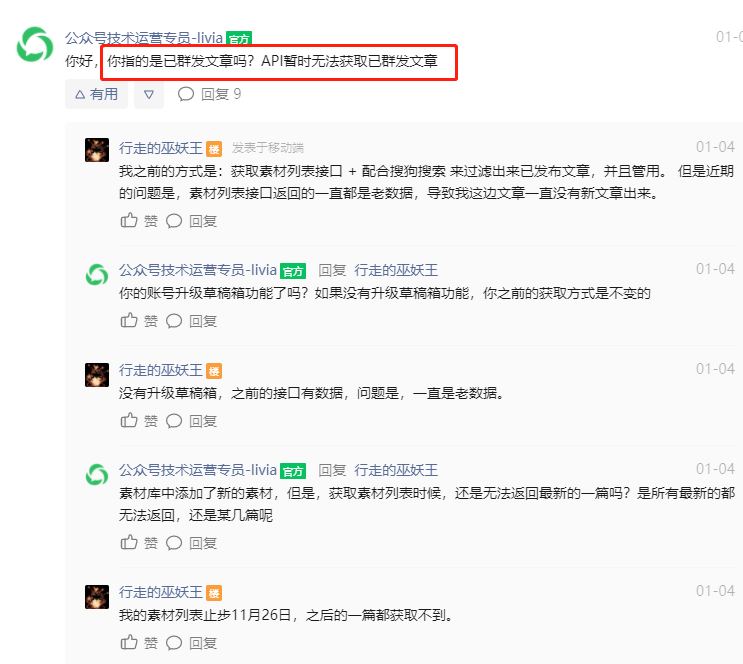
這種通過接口的方式稍微有點(diǎn)不夠完美。
還有一種方法就是通過抓取采集,但是呢微信公眾號(hào)沒有公開的網(wǎng)頁,沒辦法直接采集,唯一可能的方式就是通過搜狗微信 這個(gè)平臺(tái)來抓取,不過這個(gè)平臺(tái)只收錄文章發(fā)布比較多的微信公眾號(hào),然后只顯示最近一條公眾號(hào)記錄,而且進(jìn)行了反爬蟲設(shè)置,所以還是需要比較費(fèi)勁才能抓取到,而且需要每天定時(shí)抓取才行,不能抓取歷史發(fā)布文章。
可能最佳的方式是網(wǎng)站發(fā)布文章,通過接口同步到微信公眾號(hào),但缺陷就是網(wǎng)站后臺(tái)的編輯器沒有公眾號(hào)編輯器強(qiáng)大。
總結(jié),目前還沒有非常完美的解決方案。
如沒特殊注明,文章均為方維網(wǎng)絡(luò)原創(chuàng),轉(zhuǎn)載請(qǐng)注明來自http://www.sdlwjx666.com/news/6523.html




